常见面试题(三)

关键词: sql,面试;
今天是整理的高频hive-SQL面试题的第三弹,包含三个常见问题:
1.累计计数
我们经常需要按天或月来统计一些指标,但有时候,不仅需要计算当天或当月的数值是多少,还会涉及到累计数值,如:
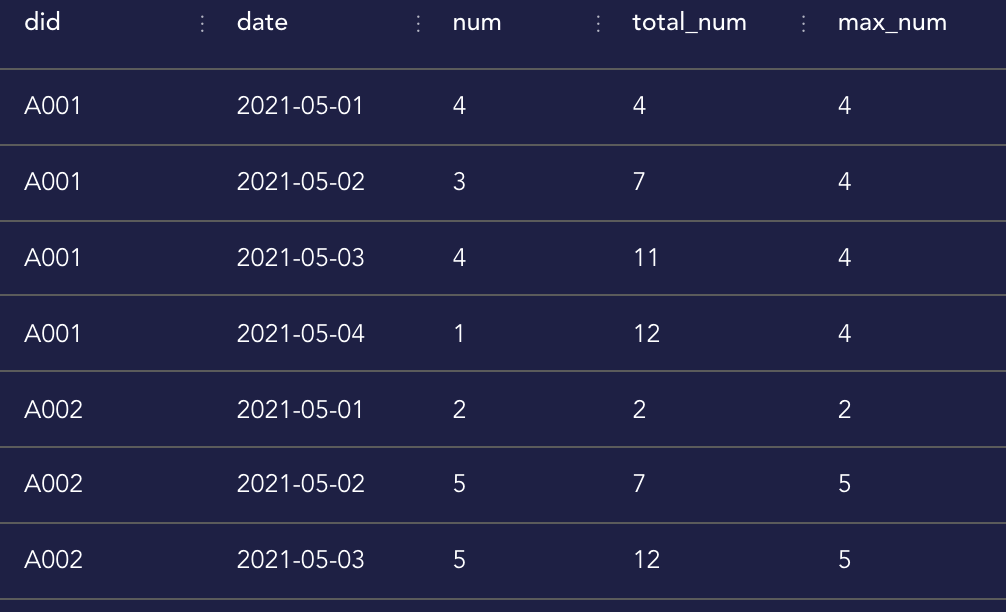
快递员派件记录表record,有pid(包裹id)、did(投递员id)、date(妥投日期)字段,请计算每个快递员每天派件数量、截止当日累计派件数量和截至当日最大单日派件量
这里考察的是利用over开窗函数进行计算的能力,需要我们将sum、max和over联用来求累计数量:
WITH record as
(SELECT 100 pid,'A001' did, '2021-05-01' date
UNION ALL SELECT 101 pid,'A001' did, '2021-05-01' date
UNION ALL SELECT 102 pid,'A001' did, '2021-05-01' date
UNION ALL SELECT 103 pid,'A001' did, '2021-05-01' date
UNION ALL SELECT 104 pid,'A001' did, '2021-05-02' date
UNION ALL SELECT 105 pid,'A001' did, '2021-05-02' date
UNION ALL SELECT 106 pid,'A001' did, '2021-05-02' date
UNION ALL SELECT 107 pid,'A001' did, '2021-05-03' date
UNION ALL SELECT 108 pid,'A001' did, '2021-05-03' date
UNION ALL SELECT 109 pid,'A001' did, '2021-05-03' date
UNION ALL SELECT 110 pid,'A001' did, '2021-05-03' date
UNION ALL SELECT 111 pid,'A001' did, '2021-05-04' date
UNION ALL SELECT 200 pid,'A002' did, '2021-05-01' date
UNION ALL SELECT 201 pid,'A002' did, '2021-05-01' date
UNION ALL SELECT 202 pid,'A002' did, '2021-05-02' date
UNION ALL SELECT 203 pid,'A002' did, '2021-05-02' date
UNION ALL SELECT 204 pid,'A002' did, '2021-05-02' date
UNION ALL SELECT 205 pid,'A002' did, '2021-05-02' date
UNION ALL SELECT 206 pid,'A002' did, '2021-05-02' date
UNION ALL SELECT 207 pid,'A002' did, '2021-05-03' date
UNION ALL SELECT 208 pid,'A002' did, '2021-05-03' date
UNION ALL SELECT 209 pid,'A002' did, '2021-05-03' date
UNION ALL SELECT 210 pid,'A002' did, '2021-05-03' date
UNION ALL SELECT 211 pid,'A002' did, '2021-05-03' date)
SELECT did,date,num,
sum(num)over(PARTITION BY did
ORDER BY date)total_num,
max(num)over(PARTITION BY did
ORDER BY date)max_num from
(SELECT did,date,count(DISTINCT pid)num
FROM record
GROUP BY did,date)x
首先,求出每个快递员每天的派件数量,作为一个字查询,然后开窗计算,按照快递员的id进行分组并按照日期升序排列,计算结果如下:
2.多维度分组
有时候我们需要对多个字段交叉进行分组计算,这时候我们会用group by将每一个维度都进行交叉分组,但实际应用的时候往往不局限于此。如:
用户属性表users包含字段uid(用户id)、province(省份)、city_level(城市等级)、gender(性别),计算省份、城市等级、性别交叉分组的用户数,各省份总用户数,各城市等级用户数,男女分别用户数,以及全部用户数
上面这道题目看起来要求很多个数,但实际上可以归为1个指标——用户数量,只不过需要从不同的维度去计算罢了。我们知道可以将需要分组的字段置于group by 关键字后,即可以把所有字段交叉进行分组,但是如果同时既要所有字段交叉分组又需要某某字段不参与分组,那么就需要拓展一下group的用法了。
(1)with cube
with cube关键字是将group by指定的N个字段的全部组合,除了每个字段的全部取值外,还会再
WITH users as
(
select 100 uid,'北京' province,'一线' city_level,'男'gender union all
select 101 uid,'北京' province,'一线' city_level,'女'gender union all
select 102 uid,'厦门' province,'二线' city_level,'男'gender union all
select 103 uid,'济南' province,'二线' city_level,'男'gender union all
select 104 uid,'济南' province,'二线' city_level,'女'gender union all
select 105 uid,'长春' province,'二线' city_level,'男'gender union all
select 106 uid,'厦门' province,'二线' city_level,'女'gender union all
select 107 uid,'北京' province,'一线' city_level,'女'gender union all
select 108 uid,'上海' province,'一线' city_level,'男'gender union all
select 109 uid,'上海' province,'一线' city_level,'男'gender union all
select 110 uid,'成都' province,'新一线' city_level,'男'gender union all
select 111 uid,'成都' province,'新一线' city_level,'男'gender union all
select 112 uid,'成都' province,'新一线' city_level,'男'gender
)
select
province,city_level,gender,count(DISTINCT uid)uv
from users
group by province,city_level,gender WITH CUBE