机器学习相关概念

错误率(Error Rate):是分类错误的样本数占样本总数的比例。
精度(Accuracy):是分类正确的样本数占样本总数的比例。
| 预测 | |||
| positive | negative | ||
| 真实 | positive | TP | FN |
| negative | FP | TN | |
为什么还需要查准率、查全率?
情景一:
错误率和精度虽然常用,但是并不能满足所有任务需求。以西瓜问题为例,假定瓜农拉来一车西瓜,我们用训练好的模型对这些西瓜进行判别,显然,错误率衡量了有多少比例的瓜被判别错误。但是若我们关心的是“挑出的西瓜中有多少比例是好瓜”,或者“所有好瓜中有多少比例被挑了出来”,那么错误率显然就不够用了,这时需要使用其他的性能度量。
情景二:
类似的需求在信息检索、Web搜索等应用中经常出现,例如在信息检索中,我们经常会关心“检索出的信息中有多少比例是用户感兴趣的”,“用户感兴趣的信息中有多少被检索出来了”。
查准率(Precision),又叫准确率,缩写表示用P。查准率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。公式表示为TP/(TP+FP)。
查全率(Recall),又叫召回率,缩写表示用R。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。召回率也就是TPR,公式表示为TP/(TP+FN)。
把所有样本都预测为positive,则FN为0,召回率就是100%,但是代价却是FP达到最大值,牺牲了准确率。为平衡多个指标,将TPR为纵轴,FPR为横轴,根据不同阈值(样本被标记为positive的概率超过阈值即被预测为positive,否则为negative),计算出TPR、FPR,并画出ROC曲线,ROC曲线下方的面积即为auc。
F1score希望同时优化的召回率和准确率。
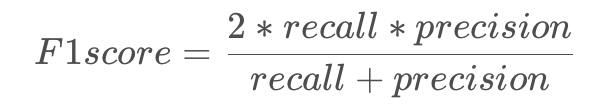
如果说召回率衡量我们训练的模型(制造的一个检验)对既有知识的记忆能力(召回率),那么两个指标都是希望训练一个能够很好拟合样本数据的模型,这一点上两者目标相同。但是auc在此之外,希望训练一个尽量不误报的模型,也就是知识外推的时候倾向保守估计,而f1希望训练一个不放过任何可能的模型,即知识外推的时候倾向激进,这就是这两个指标的核心区别。