随机森林、xgboost、gbdt的对比

关键词:
基本知识点介绍
RandomForest、XGBoost、GBDT和LightGBM都属于集成学习。
集成学习通过构建并结合多个分类器来完成学习任务,也称为多分类系统,集成学习的目的是通过结合多个机器学习分类器的预测结果来改善基本学习器的泛化能力和鲁棒性。
集成学习方法大致分为两类:
基本学习器之间存在强依赖关系、必须串行生成的序列化方法,即Boosting提升方法。基本学习器之间不存在强依赖关系、可同时生成的并行化方法,即Bagging方法。
随机森林(RandomForest)
随机森林的集成学习方法是bagging ,但是和bagging 不同的是bagging只使用bootstrap有放回的采样样本,但随机森林即随机采样样本,也随机选择特征,因此防止过拟合能力更强,降低方差。
使用的融合方法:bagging
一种集成学习算法,基于bootstrap sampling 自助采样法,重复性有放回的随机采用部分样本进行训练最后再将结果 voting 或者 averaging 。
它是并行式算法,因为不同基学习器是独立
训练一个bagging集成学习器时间复杂度与基学习器同阶(n倍,n为基学习器个数)。
bagging可以用于二分类/多分类/回归
每个基学习器的未用作训练样本可用来做包外估计,评价泛化性能。
bagging主要关注降低 方差。
两个步骤 1. 抽样训练(采样样本,采样特征) 2 融合
随机森林进一步在决策树训练时加入随机属性选择:
如果有M个输入变量,每个节点都将随机选择m(m<M)个特定的变量,然后运用这m个变量来确定最佳的分裂点。在决策树的生成过程中,m的值是保持不变的。m一般取M均方根
因此随机森林即有样本随机性(来自bagging的boostrap sampling)又有特征随机性。
随机森林的优缺点
优点:
a)随机森林算法能解决分类与回归两种类型的问题,表现良好,由于是集成学习,方差和偏差都比较低,泛化性能优越;
b)随机森林对于高维数据集的处理能力很好,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出特征的重要性程度,这是一个非常实用的功能。
c) 可以应对缺失数据;
d)当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法;
e ) 高度并行化,易于分布式实现
f) 由于是树模型 ,不需要归一化即可之间使用
缺点:
a)随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
b)对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
c) 忽略属性之间的相关性
GBDT算法(Gradient Boosting Decision Tree)
GBDT算法原理:指通过在残差减小的梯度方向建立boosting tree(提升树),即gradient boosting tree(梯度提升树)。每次建立新模型都是为了使之前模型的残差往梯度方向下降。
GBDT缺点:GBDT会累加所有树的结果,此过程无法通过分类完成,因为GBDT需要按照损失函数的梯度近似地拟合残差,这样拟合的是连续数据,因此只能是CART回归树,而不能是分类树。
XGBoost算法
XGBoost原理:XGBoost属于集成学习Boosting,是在GBDT的基础上对Boosting算法进行的改进,并加入了模型复杂度的正则项。GBDT是用模型在数据上的负梯度作为残差的近似值,从而拟合残差。XGBoost也是拟合数据残差,并用泰勒展开式对模型损失残差的近似,同时在损失函数上添加了正则化项。
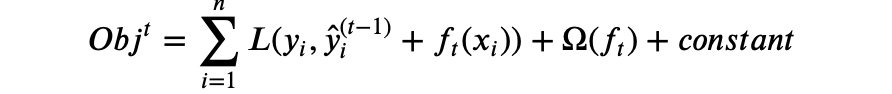
其中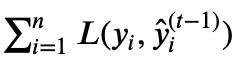 为损失函数,红色方框为正则项,包括L1、L2;红色圆圈为常数项。
为损失函数,红色方框为正则项,包括L1、L2;红色圆圈为常数项。
L1正则化项:
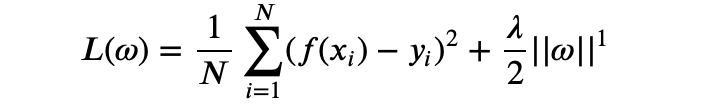
L2正则化项:
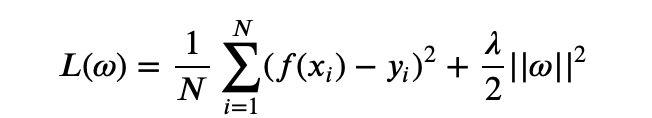
XGBoost与GBDT算法的区别:
传统的GBDT在优化的时候只用到了一阶导数信息,而XGBoost则对代价函数进行了二阶泰勒展开,得到一阶和二阶导数,并且XGBoost在代价函数中加入了正则项,用于控制模型的复杂度。另外XGBoost还支持线性分类器,通过在代价函数中加入正则项,降低了模型的方差,使学习出来的模型更加简单,避免过拟合。
GBDT的基本原理是Boosting里面的boosting tree(提升树),并使用gradient boost。其关键是利用损失函数的负梯度方向在当前模型的值作为残差的近似值,进而拟合一颗CART回归树(classification and regression tree)。
参考链接:
1.https://www.cnblogs.com/hugechuanqi/p/10554156.html
2.https://blog.csdn.net/yingfengfeixiang/article/details/80210145